逻辑回归与支持向量机的区别
- Logistics Regression
Logistics Function图像为:
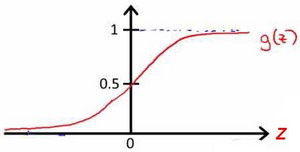
函数形式为: $g\left( z \right)=\frac{1}{1+{{e}^{-z}}}$。
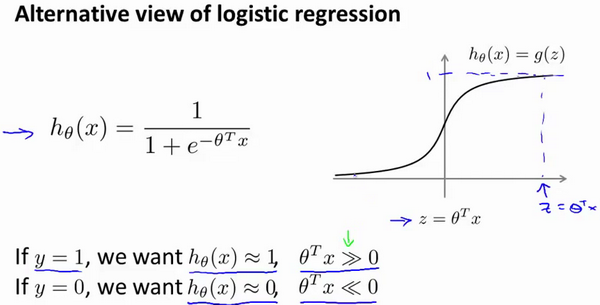
${h_\theta}\left( x \right) = g ( \theta ^ T x) = \frac{1}{1+{{e}^{-\theta ^ T x}}}$
逻辑回归的代价函数为
$J ( \theta ) = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } \operatorname { cost } \left( h _ { \theta } \left( x ^ { ( i ) } \right) , y ^ { ( i ) } \right)$
其中,
$\operatorname { cost } \left( h _ { \theta } ( x ) , y \right) = \left \lbrace \begin{aligned} - \log \left( h _ { \theta } ( x ) \right) & \text { if } y = 1 \newline - \log \left( 1 - h _ { \theta } ( x ) \right) & \text { if } y = 0 \end{aligned} \right.$
自变量是$h _ { \theta } ( x )$,而$h _ { \theta } ( x ) \in [ 0,1 ]$
需要注意的是,逻辑回归最终输出的是判定$y$归类的概率,例如$h _ { \theta } ( x ) = 0.7$,则表示70%的概率$y$归为正向类,而最终y的取值是1,代价函数取$- \log \left( h _ { \theta } ( x ) \right)$。
在逻辑回归中,我们预测:
当${h_\theta}\left( x \right) \geq 0.5$时,预测 $y=1$。
当${h_\theta}\left( x \right) < 0.5$时,预测 $y=0$ 。
记住${h_\theta}\left( x \right) = \frac{1}{1+{{e}^{-\theta ^ T x}}}$
- SVM
SVM的代价函数在Sigmoid函数取log之后修改而来,类似平移之后的Relu函数。
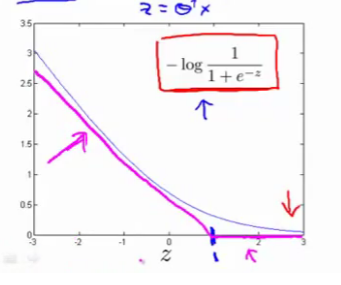
SVM被称为Large margin classifier正是归功于这个代价函数

引入kernels之后,预测方法为:给定$x$,计算新特征$f$(即kernel),当$θ^Tf \geq 0$ 时,预测 $y=1$,否则反之。
最后,一言以蔽之:we use features $ f ^ {(i)} $ instead of the original $ x ^ {(i)} $.